A few years ago I had the job of reimplementing an interface between systems we produced for two of our customers and their shared corporate Electronic Document and Records Management System (EDRMS). This was an important task because some of the documents that our systems produce must be filed in a suitable EDRMS before they become legally binding.
The particular flavour of EDRMS was HP TRIM, and in terms of integrating with a third-party API, I think this task was just about as frustrating as it could possibly have been.
In this blog post I'd like to share my experience and hopefully make someone's life a bit easier by providing some examples (which are very scarce on the web).
What is TRIM?
HP TRIM Records Management System (also known as TRIM Context) is a legacy enterprise nightmare of a tool designed to meet a vast array of US and International document storage standards. It was originally written by an Australian company called TOWER Software and later subsumed into the HP product range when they acquired the company in 2008.
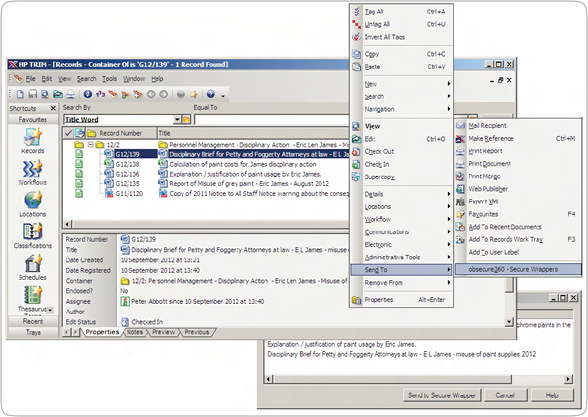
End user access to the document repository comes in the form of a clunky desktop client that looks reminiscent of the early Windows XP days and that you can imagine being designed to encourage the uptake of expensive training courses. TRIM also comes with plug-ins for just about every Microsoft tool (buttons are added to Outlook, Word, etc) for easy filing of content.
(Image source: Obsecure)
A set of database and workgroup server (application server) instances provide the back-end, which in theory should allow TRIM to scale up. In practise, I've yet to see a well-managed installation where the workgroup servers were scaled to meet demand, meaning that my experience of using TRIM is much like that of waiting for a night bus.
A note on TRIM's data model
Despite that everyone in the history of document storage just wants to put files in folders, have security controls and audit everything, the data model is completely generic. Everything, including user records, is stored as a "location", which has a type and can reference other locations. I guess you could say this was an early NoSQL database at the application level, but at the storage level it sits directly on top of a standard relational database, i.e. Oracle or SQL Server.
This is the kind of thing that gives "enterprise" applications a bad name and makes everything hundreds of times more complicated to implement than it should be. It's almost like the entire product was designed specifically to encourage the purchase of training and consultancy.
The legacy solution
In earlier versions of TRIM, there were no web service APIs to be found, but the TRIM desktop client exposes some functionality via Microsoft COM APIs, presumably designed for use by the TRIM plug-ins for Microsoft Office.
The initial developer integrating the two systems (who has long since left) decided to wrap the COM API with a Java servlet, which then exposed it properly as a web service. Due to the dependency on the TRIM desktop client, our software (and HP TRIM) was deployed to several Windows XP virtual machines that were permanently logged in as the required TRIM user.
Let's take a moment to let all of that sink in. Desktop client. Java Servlet calling out to a COM API. Windows XP. Permanently logged in user. None of this running as a proper service. To top it off, it was all supported by a third-party in a remote data centre and completely untouchable by ourselves - we didn't even have access to log files.
It sounds completely insane and hideous with hindsight, but at the time, this was probably the best (or possibly only) solution.
To the credit of everyone involved, everything ran fairly smoothly for at least 6 years. Ultimately, several factors led to its inevitable downfall:
- Poor performance of document storage and retrieval (and of course, with no access to anything we were never able to pin down the problem).
- Server hardware coming to the end of its life.
- Looming TRIM upgrades that may or may not have been compatible with the COM/Java kludge (we didn't spend much time investigating, but compatibility was looking very iffy).
- The original developer of the solution had left and the documentation for it was fairly poor.
The time had come to rework the integration. We had already established that the new version of TRIM came with a supplied SOAP service and that it was already in use on our customer's IT estate for a separate project. Initially I thought "SOAP is verbose, but at least it'll be easy". Then I started my investigation. A mere 5 minutes later, I was mentally revising my estimates for the project.
Anatomy of a SOAP service
SOAP (ironically) stands for Simple Object Access Protocol, and while an XML exchange format is simple enough in principle, it usually isn't when you do anything moderately complex - for example, sending binary data.
That said, a SOAP service is almost always defined using the Web Service Definition Language (WSDL) and this should give you a good basis upon which to build a consuming implementation by carefully defining inputs and outputs as per the following example from O'Reilly's Web Services Essentials.
<?xml version="1.0" encoding="UTF-8"?> <definitions name="HelloService" targetNamespace="http://www.ecerami.com/wsdl/HelloService.wsdl" xmlns="http://schemas.xmlsoap.org/wsdl/" xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/" xmlns:tns="http://www.ecerami.com/wsdl/HelloService.wsdl" xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <!-- Define the messages - i.e. the content to be sent or received --> <message name="SayHelloRequest"> <part name="firstName" type="xsd:string"/> </message> <message name="SayHelloResponse"> <part name="greeting" type="xsd:string"/> </message> <!-- Define the operations that use the outlined messages as inputs or outputs --> <portType name="Hello_PortType"> <operation name="sayHello"> <input message="tns:SayHelloRequest"/> <output message="tns:SayHelloResponse"/> </operation> </portType> <!-- Bind those operations to the SOAP implementation --> <binding name="Hello_Binding" type="tns:Hello_PortType"> <soap:binding style="rpc" transport="http://schemas.xmlsoap.org/soap/http"/> <operation name="sayHello"> <soap:operation soapAction="sayHello"/> <input> <soap:body encodingStyle="http://schemas.xmlsoap.org/soap/encoding/" namespace="urn:examples:helloservice" use="encoded"/> </input> <output> <soap:body encodingStyle="http://schemas.xmlsoap.org/soap/encoding/" namespace="urn:examples:helloservice" use="encoded"/> </output> </operation> </binding> <!-- Expose the bindings via a service --> <service name="Hello_Service"> <documentation>WSDL File for HelloService</documentation> <port binding="tns:Hello_Binding" name="Hello_Port"> <soap:address location="http://localhost:8080/soap/servlet/rpcrouter"/> </port> </service> </definitions>
As you can see this is an incredibly verbose way of defining a service that accepts a single string and returns another string. The request and response would look something like this (also from the O'Reilly example linked above):
<?xml version='1.0' encoding='UTF-8'?> <soap:Envelope xmlns:xsi='http://www.w3.org/2001/XMLSchema-instance' xmlns:xsd='http://www.w3.org/2001/XMLSchema' xmlns:soap='http://schemas.xmlsoap.org/soap/ envelope/' xmlns:soapenc='http://schemas.xmlsoap.org/soap/encoding/' soap:encodingStyle='http://schemas.xmlsoap.org/soap/encoding/'> <soap:Body> <n:sayHello xmlns:n='urn:examples:helloservice'> <firstName xsi:type='xsd:string'>World</firstName> </n:sayHello> </soap:Body> </soap:Envelope>
<?xml version='1.0' encoding='UTF-8'?> <SOAP-ENV:Envelope xmlns:SOAP-ENV='http://schemas.xmlsoap.org/soap/envelope/' xmlns:xsi='http://www.w3.org/1999/XMLSchema-instance' xmlns:xsd='http://www.w3.org/1999/XMLSchema'> <SOAP-ENV:Body> <ns1:sayHelloResponse xmlns:ns1='urn:examples:helloservice' SOAP-ENV:encodingStyle='http://schemas.xmlsoap.org/soap/encoding/'> <return xsi:type='xsd:string'>Hello, World!</return> </ns1:sayHelloResponse> </SOAP-ENV:Body> </SOAP-ENV:Envelope>
The major drawback to SOAP and WSDL is that the boilerplate to content ratio is off the scale. Most of it exists to help people to generate code from the definition, which is not even that beneficial for most simple services. Some of it exists to abstract the transmission layer away, i.e. so it doesn't rely on HTTP… but I suspect there are few, if any, non-HTTP SOAP services in existence.
The fact that even a tiny service is massively bloated is why most of the world is moving away from SOAP/WSDL and towards simpler models, such as REST, where the above messages would be replaced with the following HTTP request/response:
GET /sayhello/World HTTP/1.1
HTTP/1.1 200 OK Content-Type: text/xml; charset=utf-8 Content-Length: 13 Hello, World!
One thing that SOAP/WSDL does have in its favour though is that it is clearly defined. The web seems to be grappling with how to properly document REST APIs (some questioning whether they even require documentation at all), but that discussion is better held elsewhere, and solutions like RAML are starting to gain traction.
TRIM's Web Service
Ok, so having got the basics of WSDL and SOAP out of the way via the above examples, and having stated that for all of its horridness, it at least provides a clear service definition, I'm going to completely reverse my stance and state for the record that pretty much all SOAP services are rubbish to work with.
With all the richness and verbosity of WSDL and XML Schema, it should be easy to define a well-structured service, but I've yet to interact with a single third-party that did so. In the worst case, I've seen services with messages defined like this:
<message name="ServiceMessage"> <part name="input" type="xsd:any"/> </message>
Yes, that's allowing any arbitrary XML data to be passed as an input, making the assumption that the consumer will take responsibility for locating and conforming to the XML Schema of their own accord, providing no in-built documentation.
TRIM is arguably even worse, by going to completely the opposite end of the scale. The service definition provides a choice of things you can do, but no clue as to which you should use, when, or often what they even do:
<s:complexType name="TrimRequest"> <s:sequence> <s:choice minOccurs="0" maxOccurs="unbounded"> <s:element minOccurs="0" maxOccurs="1" name="KeywordRecordKeywordSelect" type="tns:KeywordRecordKeywordSelect"/> <s:element minOccurs="0" maxOccurs="1" name="RecordOperation" type="tns:RecordOperation"/> <s:element minOccurs="0" maxOccurs="1" name="AddRecordRelationship" type="tns:AddRecordRelationship"/> <s:element minOccurs="0" maxOccurs="1" name="AddLocationRelationship" type="tns:AddLocationRelationship"/> <s:element minOccurs="0" maxOccurs="1" name="AddRendition" type="tns:AddRendition"/> <s:element minOccurs="0" maxOccurs="1" name="AppendAccess" type="tns:AppendAccess"/> <s:element minOccurs="0" maxOccurs="1" name="ApplyUserLabel" type="tns:ApplyUserLabel"/> <!-- ...and another 104 lines of possibilities --> </s:choice> </s:sequence> </s:complexType>
There are a total of 111 possible input elements that may be combined within a given request. The schema says you can use 0 or 1 of each of these, but in actual fact, some are dependent on others, some are mutually exclusive with others, and none of this is documented at all. There is not a single line of annotation or documentation in the entire service "definition".
For those with morbid curiosity, I've uploaded a copy of the entire schema for you to scream at.
Working with undocumented services
This wasn't the first time I'd had to work with a completely undocumented service, and I suspect it will not be the last. My general approach is a combination of educated guesswork and trial and error; especially when the web is completely devoid of examples.
Something that I managed to make use of was the formal TRIM Web Service Reference Manual (PDF) provided by HP. I'm aware that I just stated that the service was completely undocumented; closer inspection of the PDF will reveal that it doesn't help with the SOAP/WSDL side of things at all, and instead documents some of the .NET API (but curiously, not all of it).
So, armed with some sketchy documentation, a rubbish XML Schema, a fair understanding of the existing (to-be-terminated) solution and a copy of SOAP UI, I started exploring the TRIM service that had been provided to us for development purposes.
The goal was to develop a series of representative requests and document them before writing any code. This saved us a lot of time in the long-run as it was quick to tweak XML files and re-run the request/response cycle in SOAP UI, much faster than altering code to generate the request differently.
Some example requests
To try and help people that come across this blog post out of sheer desperation while trying to solve a similar problem, here are a few example requests that I managed to get working.
Search for a record and display some results
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:trim="http://www.towersoft.com/schema/webservice/trim2/"> <soapenv:Header/> <soapenv:Body> <trim:Execute> <trim:req> <trim:RecordSearch> <trim:TargetForUpdate>false</trim:TargetForUpdate> <trim:IsForUpdate>false</trim:IsForUpdate> <!-- Limits search to 10 results --> <trim:Limit>10</trim:Limit> <!-- Sort results --> <trim:Sort1>DateCreated</trim:Sort1> <trim:Sort1Descending>false</trim:Sort1Descending> <trim:Sort2>None</trim:Sort2> <trim:Sort2Descending>false</trim:Sort2Descending> <trim:Sort3>None</trim:Sort3> <trim:Sort3Descending>false</trim:Sort3Descending> <trim:FilterFinalizedState>Both</trim:FilterFinalizedState> <trim:Uri>0</trim:Uri> <trim:IgnoreOnError>false</trim:IgnoreOnError> <!-- Search clauses go here --> <trim:RecordStringSearchClause> <trim:Arg>G12/77</trim:Arg> <trim:Type>RecordNumber</trim:Type> </trim:RecordStringSearchClause> </trim:RecordSearch> <trim:Fetch> <trim:TargetForUpdate>false</trim:TargetForUpdate> <!-- Metadata items to retrieve for each search result --> <trim:Items> <trim:SpecificationProperty> <trim:Name>recTitle</trim:Name> </trim:SpecificationProperty> <trim:SpecificationProperty> <trim:Name>recAuthor</trim:Name> </trim:SpecificationProperty> <trim:SpecificationProperty> <trim:Name>recNumber</trim:Name> </trim:SpecificationProperty> <trim:SpecificationProperty> <trim:Name>recDocumentSize</trim:Name> </trim:SpecificationProperty> <trim:SpecificationProperty> <trim:Name>recDocumentType</trim:Name> </trim:SpecificationProperty> <trim:SpecificationProperty> <trim:Name>recMimeType</trim:Name> </trim:SpecificationProperty> <trim:SpecificationProperty> <trim:Name>recRecordType</trim:Name> </trim:SpecificationProperty> <trim:SpecificationProperty> <trim:Name>recSuggestedFileName</trim:Name> </trim:SpecificationProperty> </trim:Items> <!-- Limit the result set, regardless of how many query results there are in total / top N --> <trim:Limit>10</trim:Limit> <trim:Populate>0</trim:Populate> <trim:HideVersion>false</trim:HideVersion> </trim:Fetch> <!-- Useful metadata to retrieve and log for debug there are errors or performance issues --> <trim:HideVersionNumbers>false</trim:HideVersionNumbers> <trim:ProvideTimingResults>true</trim:ProvideTimingResults> <trim:ForceRealTimeCacheUpdate>false</trim:ForceRealTimeCacheUpdate> </trim:req> </trim:Execute> </soapenv:Body> </soapenv:Envelope>
This example looks for a record called G12/77 and then lists results ordered by the date of creation. Note that the trim:Fetch element is optional, you can simply ask TRIM whether records exist or not without retrieving any metadata.
Download a file
<?xml version="1.0" encoding="UTF-8"?> <soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:trim="http://www.towersoft.com/schema/webservice/trim2/"> <soapenv:Header/> <soapenv:Body> <trim:Execute> <trim:req> <trim:ShortcutRecordNumber> <trim:TargetForUpdate>false</trim:TargetForUpdate> <trim:IsForUpdate>false</trim:IsForUpdate> <trim:Limit>1</trim:Limit> <trim:RecordNumber>G12/77</trim:RecordNumber> </trim:ShortcutRecordNumber> <trim:Fetch> <trim:TargetForUpdate>false</trim:TargetForUpdate> <trim:Items> <trim:SpecificationProperty> <trim:Name>recSuggestedFileName</trim:Name> </trim:SpecificationProperty> </trim:Items> <trim:Limit>1</trim:Limit> <trim:Populate>0</trim:Populate> <trim:HideVersion>false</trim:HideVersion> </trim:Fetch> <trim:Download> <trim:TargetForUpdate>false</trim:TargetForUpdate> <trim:Checkout>false</trim:Checkout> <trim:MaximumTransferBytes>0</trim:MaximumTransferBytes> <trim:TransferInset>0</trim:TransferInset> <trim:TransferType>inline</trim:TransferType> </trim:Download> <trim:HideVersionNumbers>false</trim:HideVersionNumbers> <trim:ProvideTimingResults>true</trim:ProvideTimingResults> <trim:ForceRealTimeCacheUpdate>false</trim:ForceRealTimeCacheUpdate> </trim:req> </trim:Execute> </soapenv:Body> </soapenv:Envelope>
This "downloads" a file from record G12/77 (as a base64 encoded string) and retrieves its filename.
Create a record
<?xml version="1.0" encoding="UTF-8"?> <soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:trim="http://www.towersoft.com/schema/webservice/trim2/"> <soapenv:Header/> <soapenv:Body> <trim:Execute> <trim:req> <trim:ShortcutRecordNumber> <trim:TargetForUpdate>false</trim:TargetForUpdate> <trim:IsForUpdate>false</trim:IsForUpdate> <trim:Limit>1</trim:Limit> <trim:RecordNumber>99.99.99/1A</trim:RecordNumber> </trim:ShortcutRecordNumber> <trim:FetchInjectionUri> <trim:TargetForUpdate>false</trim:TargetForUpdate> <trim:Id>parentfolder</trim:Id> </trim:FetchInjectionUri> <trim:Create> <trim:TargetForUpdate>false</trim:TargetForUpdate> <trim:Saving>false</trim:Saving> <trim:VerifyAndCreateWarning>true</trim:VerifyAndCreateWarning> <trim:Items> <trim:InputProperty> <trim:Name>recContainer</trim:Name> <trim:Val>inject:parentfolder</trim:Val> </trim:InputProperty> <trim:InputProperty> <trim:Name>recTitle</trim:Name> <trim:Val>Test PDF Filing</trim:Val> </trim:InputProperty> <trim:InputProperty> <trim:Name>recRecordType</trim:Name> <trim:Val>name:Document</trim:Val> </trim:InputProperty> <trim:InputProperty> <trim:Name>recAuthorLoc</trim:Name> <trim:Val>4</trim:Val> </trim:InputProperty> </trim:Items> <trim:TrimObjectType>record</trim:TrimObjectType> </trim:Create> <trim:HideVersionNumbers>false</trim:HideVersionNumbers> <trim:ProvideTimingResults>true</trim:ProvideTimingResults> <trim:ForceRealTimeCacheUpdate>false</trim:ForceRealTimeCacheUpdate> </trim:req> </trim:Execute> </soapenv:Body> </soapenv:Envelope>
This example creates a record in preparation for file storage. The interesting thing about it is that it does several things in combination…
- Look up the folder in which to create the new record ("99.99.99/1A").
- Alias the internal reference for that older to the URI "parentfolder".
- Create a record with the provided properties, injecting the "parentfolder" URI.
This is kinda neat, as it allows you to look up the parent folder's internal reference without having to use a separate request/response cycle.
Uploading a file to a record
I found this one really weird. You have to upload a file, hold a reference to that file, and then bind it to a record… instead of say, "here's a payload, put it in this record".
<?xml version="1.0" encoding="UTF-8"?> <soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:trim="http://www.towersoft.com/schema/webservice/trim2/"> <soapenv:Header/> <soapenv:Body> <trim:Execute> <trim:req> <trim:Upload> <trim:TargetForUpdate>false</trim:TargetForUpdate> <trim:BytesRead>0</trim:BytesRead> <trim:Final>false</trim:Final> <trim:TransferType>inline</trim:TransferType> <trim:Base64Payload> <!-- Snipped, insert your payload here as a base64 string --> </trim:Base64Payload> </trim:Upload> <trim:HideVersionNumbers>false</trim:HideVersionNumbers> <trim:ProvideTimingResults>true</trim:ProvideTimingResults> <trim:ForceRealTimeCacheUpdate>false</trim:ForceRealTimeCacheUpdate> </trim:req> </trim:Execute> </soapenv:Body> </soapenv:Envelope>
This is followed by the aforementioned "binding" request:
<?xml version="1.0" encoding="UTF-8"?> <soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:trim="http://www.towersoft.com/schema/webservice/trim2/"> <soapenv:Header/> <soapenv:Body> <trim:Execute> <trim:req> <trim:ShortcutRecordUri> <trim:TargetForUpdate>false</trim:TargetForUpdate> <trim:IsForUpdate>true</trim:IsForUpdate> <trim:Limit>1</trim:Limit> <trim:Uri>59</trim:Uri> </trim:ShortcutRecordUri> <trim:CheckIn> <trim:TargetObjectType>name:Document</trim:TargetObjectType> <trim:TargetForUpdate>false</trim:TargetForUpdate> <trim:FailOnWarning>true</trim:FailOnWarning> <trim:DocumentExtension>.pdf</trim:DocumentExtension> <trim:NewRevision>false</trim:NewRevision> <trim:KeepCheckedOut>false</trim:KeepCheckedOut> <trim:UploadId>tmp56F2.tmp</trim:UploadId> </trim:CheckIn> <trim:Finalize> <trim:TargetForUpdate>false</trim:TargetForUpdate> <trim:FailOnWarning>true</trim:FailOnWarning> </trim:Finalize> <trim:HideVersionNumbers>false</trim:HideVersionNumbers> <trim:ProvideTimingResults>true</trim:ProvideTimingResults> <trim:ForceRealTimeCacheUpdate>false</trim:ForceRealTimeCacheUpdate> </trim:req> </trim:Execute> </soapenv:Body> </soapenv:Envelope>
The trim:UploadId must be set to a value returned in the response to the first file upload request. This, terrifyingly, always seems to be a temporary filename. I really hope the file isn't placed anywhere where it could be deleted before the second request is sent.
Something curious about this second message is that you specify the file type by using the file extension (i.e. ".pdf") instead of the content type. I find this particularly disturbing because you have to assume that there is a registered list of file extensions that TRIM recognises, as opposed to just taking in a complete filename and content type and letting the client get on with it when the records are viewed.
Note: I've passed in the record URI directly in trim:Uri here, as we've already established it in a prior request (our implementation always creates a new record for each file to be uploaded). You can perform similar chaining to that seen earlier (using the URI injection mechanism) to look up the record and perform this binding in one go if you're reusing an existing record.
The good, the bad and the ugly
I didn't end up hating the service - it's actually fine, if clunky. The most frustrating part was having to figure out everything from scratch.
The good
- Generally, the request "feature" chaining syntax is pretty nice - a single request can achieve multiple goals.
- I like that you can look up values and inject them into another part of the request, reducing the number of requests needed, I don't think I've seen this concept in any other API.
- It's possible to chunk uploads, by splitting them into multiple requests… this is great for sending larger files.
The bad
- The incredibly awful idea of having a large XML schema, and then not documenting any of it.
- The XML schema doesn't actually define the possible message structures at all, it just tells you every possible thing you can do and lets you figure out which ones work together and which do not (despite this idea being simple to express in XML schema).
- Due to everything being generic and configurable, there is no real documentation for what a TRIM instance will have in terms of metadata, so you have to perform a series of initial "lookup" requests, just so you know what you're dealing with.
- It seemed like a very flaky service at best, even over a local network. I quite often got weird errors that went away given the passage of time.
The ugly
Introducing one of the weidest things I've seen so far as a developer, hopefully the world's only implementation of Reverse Polish Notation in XML:
<trim:RecordStringSearchClause> <trim:Arg>G12/77</trim:Arg> <trim:Type>RecordNumber</trim:Type> </trim:RecordStringSearchClause> <trim:RecordStringSearchClause> <trim:Arg>G12/78</trim:Arg> <trim:Type>RecordNumber</trim:Type> </trim:RecordStringSearchClause> <trim:RecordOrSearchClause/>
Yep, that's accurate. The operation follows the two operands:
<OPERAND/> <OPERAND/> <OR/>
…instead of nesting elements as you'd normally expect to see in XML:
<OR> <OPERAND/> <OPERAND/> </OR>
I spent a good while puzzling over the error messages I received when trying the nested XML syntax before I discovered the secret.
The worst part is that the error message didn't even give me any clues, I ended up finding this out from the .NET API documentation, which not only explained Reverse Polish Notation, but also gave some code samples:
RecordStringSearchClause titleword = new RecordStringSearchClause(); titleword.Type = RecordStringSearchClauseType.TitleWord; titleword.Arg = "Reef"; RecordDateRangeSearchClause date = new RecordDateRangeSearchClause(); date.Type = RecordDateRangeSearchClauseType.DateRegistered; date.StartTime = "1/4/1990"; date.EndTime = "25/1/2005"; RecordAndSearchClause andclause = new RecordAndSearchClause(); search.Items = new RecordClause[] {titleword, date, andclause}; request.Items = new Operation[] {search, fetch};
Note the ordering of titleword, date and andclause.
Something I also noted from this was that the object names are often identical, or very, very similar to the XML elements in the schema. I suspect the SOAP implementation was bolted on as an after-thought, which might explain the quality and some of the XSD "design".
I very much enjoyed the following example of "even more complex search queries using multiple Boolean clauses":
{titleword, date1, andclause, titleword, date2, andclause, orclause};
Reverse Polish Notation in an API. Totally bonkers.
Summary
The TRIM web service is the kind of thing I'd expect to follow on from overly generic solutions designed to meet large, sprawling international standards. It works reasonably well, and we were able to achieve our stated goal of decommissioning our legacy integration without investing unreasonable amounts of time or effort.
The lack of documentation made this project about ten times harder than it really needed to be, but once we'd got working prototype requests in SOAP UI, building an implementation around this was a fairly standard development exercise.
Overall, there were some things I liked and some I didn't, but given the madness of the API, I do wonder what the internal code looked like - probably something that would end up on The Daily WTF.
I hope someone out there finds this interesting or useful, there's not a huge wealth of information on the TRIM web services out there. If you have any questions about the API or would like to see other sample requests, please leave a comment and I'll do my best to oblige.